머신러닝 분류분석모델링을 배워봤는데 방식들이 비슷해서 배우기가 쉽다. 데이터분석처럼 문법이 여러가지인것도 아니라 머신러닝이 더 쉬운것 같다.
분류분석모델링의 프로세스
1. 표준화 or 정규화로 스케일링
2. 데이터를 학습용(train) / 실험용(test)으로 나눈다
3. 컴퓨터한테 어떤 펭귄의 '종'과 부리길이, 두께, 몸무게같은 변수를 던져준다.
4. 컴퓨터가 연관관계를 학습
5. 반대로 부리길이, 부리두께 같은 변수를 던지면 컴퓨터가 학습한 정보를 토대로 맞춘다. ex) 이 펭귄은 아델리다.
6. test용 데이터를 몇개 던져줘서 몇% 맞췄는지 확인
sklearn에서 제공하는 penguins 데이터로 해봤는데 99%정도 맞추고 무당수준인데 seaborn으로 그래프를 그려보면 감이온다.

결측치 제거

강의에서 정규화로 스케일링하길래 정규화로 먼저해봤다.
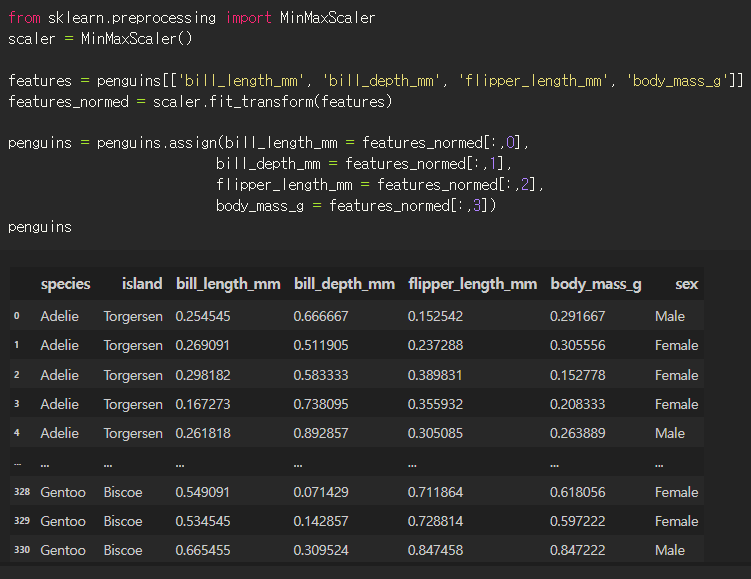
라벨인코더로 텍스트도 수치로 바꿔주면 완료. 이제 DataFrame의 값들이 모두 숫자라 머신러닝할 준비가 끝났다.

데이터의 80%는 학습시키고(train) 나머지20%는 검증을 위해 남겨둔다(test)
여러가지 변수중 종을 확인하고 싶어서 'species'를 기준으로
X에는 종빼고 나머지 데이터를, Y에는 종만 있는 결과데이터를 넣어준다.

각 변수별로 값이 잘 담겼는지 확인해본다.



첫번째 방법 : 로지스틱회귀
강의로 배울때는 성별(두가지)이였고 나는 이번에 종(세가지)로 하는거라 로지스틱이 될까 했는데 결과값이 만족스러웠다.
왜 되는걸까?..
아래처럼 lr_model.fit(X_train, Y_train) 명령어를 입력하면 학습을 시작한다

학습이 끝났으면 테스트값을 넣어주고 결과값을 뱉어보라고 시키면 값을 뱉는다

테스트의 첫번째 행은 Chinstrap, 두번째는 Gentoo, 세번째는 Adelie.. 이런식으로 컴퓨터가 문제를 풀었는데 실제로 맞을까?
Y_test : 실제 Y값,
predictions : X_test데이터를 기반으로 한 Y의 예측값

정답율이 100%
다른 모델들도 바로 돌려보면
2. KNeighborsClassifier

from sklearn.metrics import accuracy_score <- 이거는 위에서 했으니 사실 빼도된다.
3.DecisionTreeClassifier
실수로 같은 Cell 여러번 돌려봤는데 얘는 돌릴때마다 정확도가 다르게나온다. 다른 모델링은 다 똑같이 고정임

4. SVC(서포트벡터분류기)

학습용과 검증용 데이터가 임의에서 추출되는거라 (스케일링 과정에서 shuffle=True) 주피터노트북을 돌릴때마다 정확도가 바뀐다. 한번 더 돌리니까 이렇게나온다.

'파이썬. 머신러닝 > sklearn' 카테고리의 다른 글
| 나도코딩_머신러닝 1 : 선형 회귀, 데이터 세트 분리 (0) | 2024.07.30 |
|---|---|
| sklearn : 분류분석모델링 - 펭귄 종 맞추기 vs 성별 맞추기 (0) | 2022.10.19 |
| sklearn : 전처리 - 원핫 인코딩(One Hot Encoding) (0) | 2022.10.13 |
| sklearn : 전처리 스케일링(Scaling) - 표준화(Standardization) (0) | 2022.10.12 |
| sklearn : 전처리 스케일링(Scaling) - 정규화(Normalization) (0) | 2022.10.10 |



