혼자 공부하는 데이터분석 116p~
도서리스트 가져오기
(이것도 도서200개인데, 이전에 실습한 자료랑 다른 데이터긴함)



requests 로 웹 페이지에 HTTP 요청을 보내고 웹페이지에서는 HTML 코드를 보내준다

requests.get(보내고 싶은 url주소)을 통해 웹 페이지에 요청을하고 응답온 거를 r 변수에 다시 넣는다.
그러면 이렇게 HTML 코드로 온다.

HTML 코드가 엄청 긴데 여기서 나는 YES24 상세페이지에 들어가는 태그를 찾아야된다.
크롬 개발자 도구로 이거를 쉽게 찾을 수 있다.

크롬 창에서 F12누르면 바로 개발자 도구로 이동하고 (우측에 보이는 코드들이 다 HTML코드다)
1번에 있는 버튼을 누르고(ctrl+shift+c) 웹페이지에 마우스 커서를 올리면 해당 부분 태그가 어디있는지 하이라이트 해준다
2번(상세설명)이 필요하니까 2번에 커서를 올리거나 클릭을 하면 오른쪽에서 태그가 있는 코드를 하이라이트 해준다.
이제 여기서 BeautifulSoup 패키지를 사용한다 HTML코드를 찾는 역할을 한다.

BeautifulSoup(파싱할 HTML문서, 파서)
파서: 입력 데이터를 받아 데이터 구조를 만드는 소프트웨어 라이브러리
ㄴ예) json 패키지, xml 패키지가 JSON, XML을 위한 파서
파싱: 이런 과정을 파싱한다고 함.
class가 gd_name인 a태그를 찾기

여기서 url로 사용할 href를 가져온다

이 새로운 URL을 이용해서 상세페이지의 HTML 코드를 가져온다.

아까 했던거를 한번 더 한다. 크롬 개발자모드 들어가서 내가 원하는 부분에 HTML 코드를 보고

BeautifulSoup를 이용해서 HTML코드를 찾는다


빨간줄로 그은, 내가 원하는 태그를 뽑기위해 find_all 메서드를 사용한다
find() : 괄호안에 있는 이름을 가진 첫번째 태그를 찾는다(엑셀같네)
find_all(): 괄혼안에 있는 이름을 가진 모든 태그를 찾는다
※ find_all은 여러 태그를 뽑기때문에 list형식으로 출력한다.

list에 순환문을 활용하여 쪽수를 뽑아내면 된다.
get_text()는 tag안에 있는 값을 뱉어낸다.

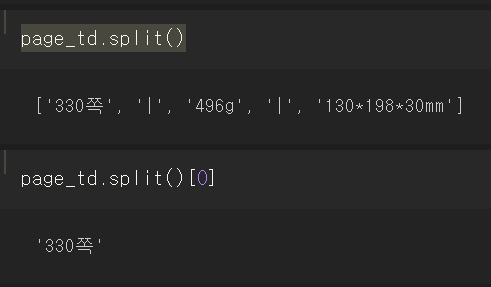
이제 순환문으로 만들차례

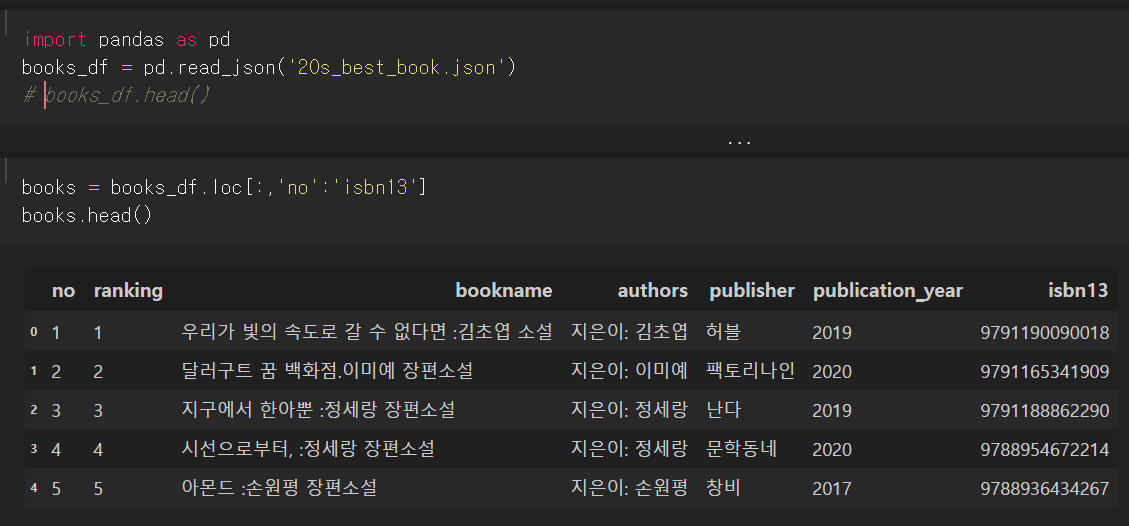
이 부분부터 이해안간다....

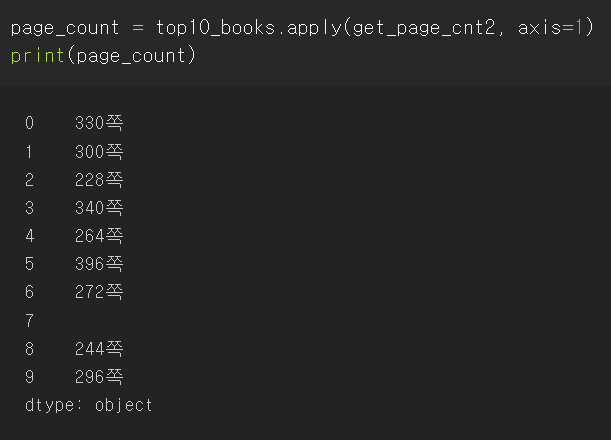

최종결과

'파이썬. 데이터분석 > 웹스크래핑' 카테고리의 다른 글
| find(), find_all(), .string, get_text() 링크 (0) | 2024.06.06 |
|---|