https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.duplicated.html
pandas.DataFrame.duplicated — pandas 1.4.2 documentation
Only consider certain columns for identifying duplicates, by default use all of the columns.
pandas.pydata.org

duplicated => Boolean형식의 Series를 내뱉는다. 중복값있는지 확인하는 용도
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
pandas.DataFrame.drop_duplicates — pandas 1.4.2 documentation
next pandas.DataFrame.droplevel
pandas.pydata.org

duplicates ==> DataFrame을 제거하여 DataFrame을 내뱉는다. 옵션은 subset, keep, inplace, ignore_index있다.
DataFrame df
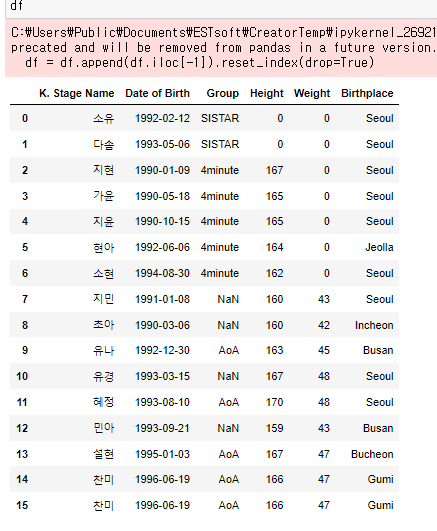

subset 옵션을 이용해서 특정 column을 선택할 수 있다.

subset list형식이 가능하다
keep='first'가 default값, 중복되면 첫번째값을 유지한다(keep)는 말. 엑셀 중복데이터 제거랑 똑같다고 보면됨.
ignore_index='False'가 default값, True면 데이터제거후에 인덱스를 바로 셋팅해준다 (reset.index 기능)

'파이썬. 데이터분석 > Pandas' 카테고리의 다른 글
| Pandas DataFrame : apply, lambda (0) | 2022.06.22 |
|---|---|
| Pandas DataFrame : isnull, replace, fillna, dropna 결측치처리 (0) | 2022.06.21 |
| Pandas DataFrame : replace (0) | 2022.06.20 |
| Pandas DataFrame : 데이터 바꾸기 (0) | 2022.06.19 |
| Pandas DataFrame : reset_index (0) | 2022.06.19 |


