본격적인 머신러닝을 배우다보니 새로운 단어를 많이 접했는데, 일반적으로도 사용되는 통계용어다.
수치를 분석할 때 단위나 스케일 차이가 크면 학습모델 성능이 저하된다.
데이터 단위를 맞춰주는 작업을 스케일링이라고 함.
스케일링의 종류에는 정규화(Normalization)와 표준화(Stadardization)가 있는데 이번엔 정규화를 정리한다.

정규화는 값들을 0~1 범위내로 옮기는 것. MinMaxScaler를 이용해서 값들을 0~1사이로 옮긴다
(측정값-최솟값) / (최댓값 - 최솟값)
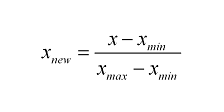
데이터 불러오기

전처리안한 데이터를 그대로 히스토그램으로 만들면 아까 말한 것처럼 단위가 달라서 이렇게 된다.

sklearn의 MinMaxScaler를 import해서 전처리

features_normed를 보면 array 형식으로 나온다

정규화되어있기 전 모습(그냥 penguins 데이터의 copy)

기존 DataFrame에 assign함수를 이용해서 정규화된 array를 인덱싱으로 첫번째, 두번째, 세번째, 네번째를 집어넣어서 교체해준다

위를 보면 0~1의 값으로 깔끔하게 바뀌어있다.

뭔가 복잡하지만 그래도 x축을 보면 0~1의 값으로 맞게 바뀌어진 게 확인된다.
'파이썬. 머신러닝 > sklearn' 카테고리의 다른 글
| 나도코딩_머신러닝 1 : 선형 회귀, 데이터 세트 분리 (0) | 2024.07.30 |
|---|---|
| sklearn : 분류분석모델링 - 펭귄 종 맞추기 vs 성별 맞추기 (0) | 2022.10.19 |
| sklearn : 분류분석모델링(Logistic Regreesion, K-Neighbors, Decision Tree, SVC) (0) | 2022.10.19 |
| sklearn : 전처리 - 원핫 인코딩(One Hot Encoding) (0) | 2022.10.13 |
| sklearn : 전처리 스케일링(Scaling) - 표준화(Standardization) (0) | 2022.10.12 |



